- Outstanding Сasual Dating - Genuine Damsels
- Finest Сasual Dating - Verified Damsels
- Premier Сasual Dating - Living Women
- @pump_upp - best crypto pumps on telegram !
- National *** Days
- العالم الافتراضي الخيار الثنائي برو الإصدار 20
- ما هو مستقبل الخيار الثنائي
- الاتجاه التالي استراتيجية الخيارات الثنائية
- ساخت خنک کننده با کمپرسور
- خریدار مادربرد x58

آخرین مطالب
امکانات وب
با سلام به همه دوستان گلم@};-
لیزا سو همه رو غافل گیر کرد و نشان داد که موفقیت رایزن چقدر در بودجه آنها تاثیر گذاشته است
و بزرگترین تغییر معماری که اون رو اصلا یک نسل جدید برای سال های آینده سخت افزار می کنه داریم
RDNA طراحی شده برای تمام بازارهای سرور و بازی کامپیوتری تا موبایل هست
و سامسونگ این معماری را برای گرافیک موبایل های آینده اش لیسانس کرده
بعد از معماری VLIW که از ILP استفاده میکرد که نقاط قوت و ضعف خودش را داشت
GCN معرفی شد که شیوه مخصوص به خودش از بهره بری از SIMT را دارد
GCN به منظور دریافت و ظرفیت بالای اطلاعات طراحی شده بود
در این معماری میزان وابستگی به نتایج اطلاعات دیگر هیچ گونه تاثیری در سرعت پردازش نداشته است
و میزان تاخیر محاسبات همیشه یکسان بوده . تمام پردازش ها باید چهار CYCLE طول می کشیدند
و برای اینکه این میزان تاخیر بالا پوشش داده شود ورودی و همزمانی اطلاعات بالایی داشت تا SIMD ها بیکار نمانند
نقطه ضعف این معماری در همیشه ثابت بودن سرعت پردازش و تاخیر بالا در پردازش های تک مرحله ای و تک نخی هست
rdna طراحی شده مخصوص تاخیر پایین و بازدهی پردازش های تک نخی هست
بخش واحد محاسباتی شدر ها cu از پایه تغییر کرده است .
پذیرش و ارسال محاسبات در هر یک چرخه رسیده است و هیچ احتیاجی برای منتظر بودن برای چرخه های بیشتر نیست
ظرفیت نخ simd به 32 تبدیل شده که این میزان متناسب با اطلاعاتی که خودشان بهتر میدانند انتخاب شده
هر cu می تواند WAVE-FRONT های 32 نخی در یک چرخه یا همانند نسل قبل 64 نخی داشته باشد اما در دو چرخه
بخش SCALAR که در نسل قبل فقط یکی بود الان دو تا شده . (با توجه به دو تا SIMD 32 و دو اسکالر دیگر تعداد چهار ALU مستقل حفظ شده)
این اسکالر ها برای از بین بردن نتایج و پردازش های وابسته به صورت سریع مفید هست
برای پردازش تک نخی در نسل قبل باید چهار چرخه معطل می شد که الان در همان چرخه ارسال میشود
حالت معطلی اولیه برای تقسیم بندی و دسته بندی همانند gcn وجود ندارد
و هر دستور العمل با هر تعداد چرخه در همان ابتدا می توانند به هر صورتی بین شدر ها تقسیم شوند
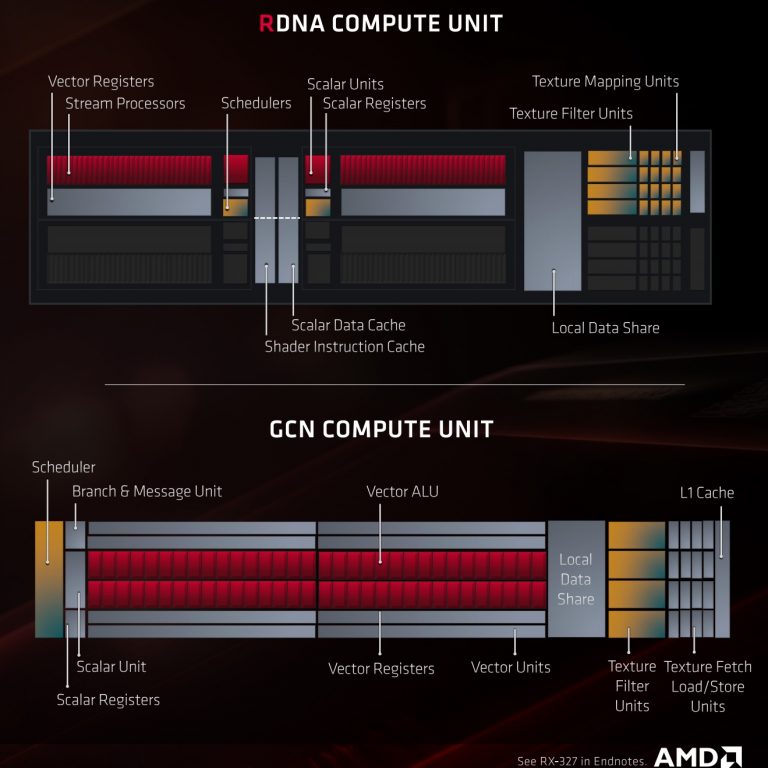
در معماری قبلی یک بخش دسته بندی بزرگ داشت که الان دو قسمت کوچک شده
دو cu در کنار هم میتوانند اطلاعات اشتراکی باهم داشته باشند که در کنار یک cu بزرگتر را می سازند
جدا از سرعت بالای تک نخی این معماری نه تنها چیزی از GCN کم ندارد
بلکه با این تکنیک ها نیز میتواند پردازش هایی که سرعت بالایی احتیاج ندارند را همانند نسل قبل ظرفیت بالایی داشته باشد

IPC به معنای دستور العمل های در هر کلاک هست.
VLIW نشان داده که در بعضی از محاسبات بهتر از SIMT پردازش را محاسبه میکند
اما اجازه دستکاری کامپایلر و بهینه سازی برای انواع دیگر محاسبات خیلی پایینی داشته
در صورت ایدئال بودن کد ها برای یک WAVEFRONT میزان IPC 1.25 می دهد
در gcn این میزان نرخ ثابت 0.25 هست که در چهار کلاک یک WAVE را تکمیل می کند
RDNA از تکنیک های جدید کامپایلر و فوق استاندارد استفاده میکند که در حالت ایدئال نرخ 1 را میدهد
شایستگی نام RDNA زمانی مشخص می شود که این معماری تمام قابلیت های نسل های پیشین را دارد
مهم ترین دستاورد توانایی اجرای ILP در کنار SIMT هست که یک جهان جدیدی از قابلیت های ممکن را باز میکند

الان از بخش CU خارج می شویم
گفته شده که ناوی از RDNA نسخه اول استفاده میکند
و علت ان بهره وری از بهینه سازی هایی هست که برای GCN استفاده شده است
در غیر این صورت همانند اوایل GCN بازدهی پایینی خواهد داشت و عملا تمام بهینه سازی های قبلی را دور انداخته بودنند
بعد از جا افتادن کدنویسی های مخصوص CU های ان به لطف کنسول ها
RDNA نسخه دو که از RAY TRACING به صورت شتاب دهند سخت افزاری بهره می برد؛خواهد امد

اما با این حال ناوی حرف های زیادی خارج از CU برای گفتن دارد
در ابتدا تاخیرات کش های L1 و L2 و پهنای باند انها افزایش پیدا کرده است
تکنیک فشرده سازی رنگ در سطح عمیق استفاده شده که پهنای باند بین اجزای داخلی گرافیک را نیز افزایش داده
و بخش های جئومتری و خود پردازنده های شدر می توانند مستقیم الگوریتم فشرده را بخوانند و بنویسند !!!!
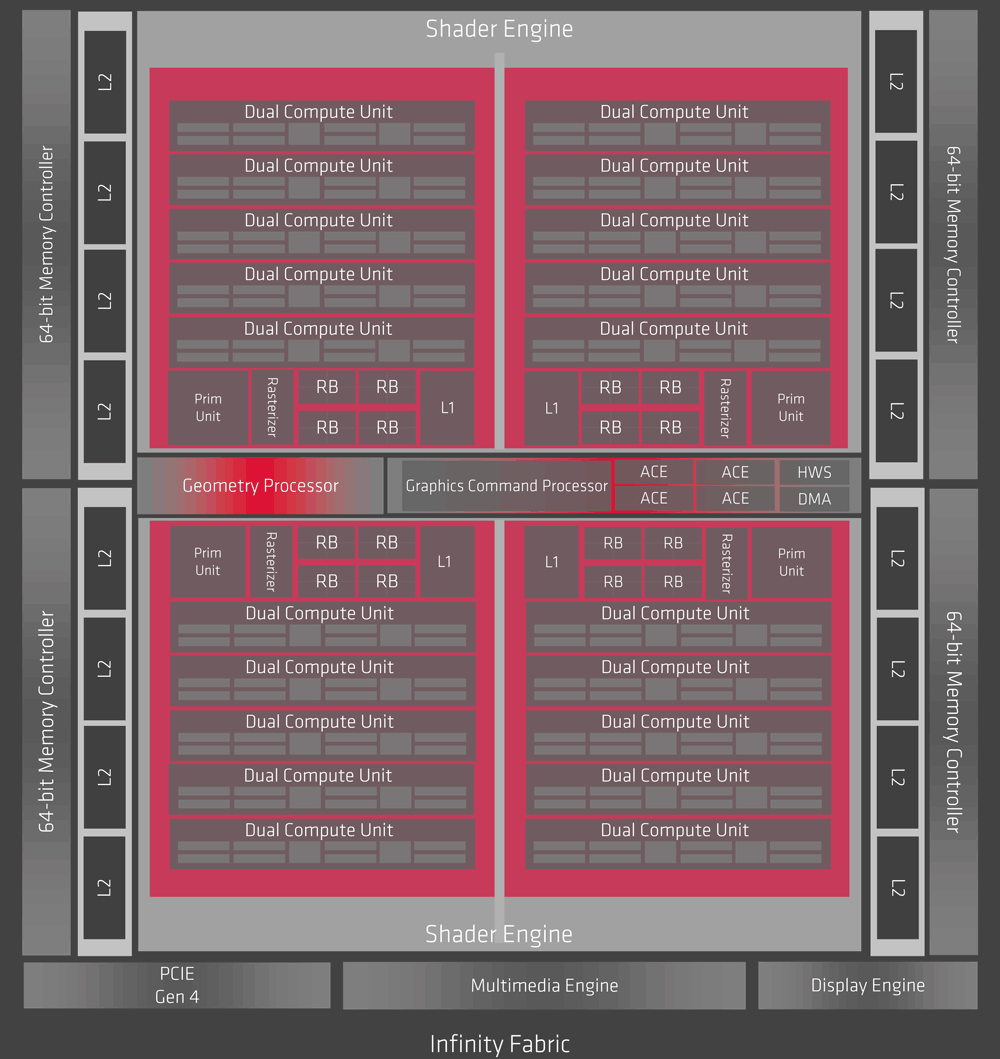
گفته شده از فلسفه طراحی ذن استفاده شده و هدف معماری با قابلیت SCALABLE بوده
این معماری را میتوان به بخش های یکسان با تعداد اجزای یکسان تقسیم کرد!!!!
در ناوی بخش مرکزی جئومتری وجود دارد که به اجزای PRIM UNIT دستور میدهد و تماما وظایف خودکار و بدون دخالت دارد!!!
ASYNC نه تنها تاخیر پایینی دارد بلکه توانسته در موارد ضروری با CONTEXT SWITCH همانند انویدیا و با سرعت دیگر پردازش ها را متوقف کند و منابع سخت افزاری بیشتر به خودش بدهد
این کار خیلی به واقعیت مجازی و vr کمک میکند
همچنین به لطف ان AMD از قابلیت ضد لگ و تاخیر پایین را در نرم افزار خودش معرفی کرده که با فعال کردن ان لگ و پاسخ دهی بالا میرود
ناوی در تعداد هسته و سطح تراشه همانند پولارس هست اما با لیتوگرافی 7 نانومتری و تعداد ترانزیستور خیلی بالاتر و مموری GDDR6
و بازدهی قویتری از وگا 64 با چهار هزار پردازنده شدر
30 درصد بهینگی و بازدهی رو فقط به لیتوگرافی اختصاص میدهیم . اما 20 درصد بازدهی بیشتر به خود معماری هست
و با کد نویسی های اختصاصی خیلی بیشتر نیز خواهد شد
اسلاید های کامل و کیفیت بالا در این لینک وجود دارد
https://gpureport.cz/info/Graphics_A...e_06102019.pdf
مرجع اورکلاک...لیزا سو همه رو غافل گیر کرد و نشان داد که موفقیت رایزن چقدر در بودجه آنها تاثیر گذاشته است
و بزرگترین تغییر معماری که اون رو اصلا یک نسل جدید برای سال های آینده سخت افزار می کنه داریم
RDNA طراحی شده برای تمام بازارهای سرور و بازی کامپیوتری تا موبایل هست
و سامسونگ این معماری را برای گرافیک موبایل های آینده اش لیسانس کرده
بعد از معماری VLIW که از ILP استفاده میکرد که نقاط قوت و ضعف خودش را داشت
GCN معرفی شد که شیوه مخصوص به خودش از بهره بری از SIMT را دارد
GCN به منظور دریافت و ظرفیت بالای اطلاعات طراحی شده بود
در این معماری میزان وابستگی به نتایج اطلاعات دیگر هیچ گونه تاثیری در سرعت پردازش نداشته است
و میزان تاخیر محاسبات همیشه یکسان بوده . تمام پردازش ها باید چهار CYCLE طول می کشیدند
و برای اینکه این میزان تاخیر بالا پوشش داده شود ورودی و همزمانی اطلاعات بالایی داشت تا SIMD ها بیکار نمانند
نقطه ضعف این معماری در همیشه ثابت بودن سرعت پردازش و تاخیر بالا در پردازش های تک مرحله ای و تک نخی هست
rdna طراحی شده مخصوص تاخیر پایین و بازدهی پردازش های تک نخی هست
بخش واحد محاسباتی شدر ها cu از پایه تغییر کرده است .
پذیرش و ارسال محاسبات در هر یک چرخه رسیده است و هیچ احتیاجی برای منتظر بودن برای چرخه های بیشتر نیست
ظرفیت نخ simd به 32 تبدیل شده که این میزان متناسب با اطلاعاتی که خودشان بهتر میدانند انتخاب شده
هر cu می تواند WAVE-FRONT های 32 نخی در یک چرخه یا همانند نسل قبل 64 نخی داشته باشد اما در دو چرخه
بخش SCALAR که در نسل قبل فقط یکی بود الان دو تا شده . (با توجه به دو تا SIMD 32 و دو اسکالر دیگر تعداد چهار ALU مستقل حفظ شده)
این اسکالر ها برای از بین بردن نتایج و پردازش های وابسته به صورت سریع مفید هست
برای پردازش تک نخی در نسل قبل باید چهار چرخه معطل می شد که الان در همان چرخه ارسال میشود
حالت معطلی اولیه برای تقسیم بندی و دسته بندی همانند gcn وجود ندارد
و هر دستور العمل با هر تعداد چرخه در همان ابتدا می توانند به هر صورتی بین شدر ها تقسیم شوند
در معماری قبلی یک بخش دسته بندی بزرگ داشت که الان دو قسمت کوچک شده
دو cu در کنار هم میتوانند اطلاعات اشتراکی باهم داشته باشند که در کنار یک cu بزرگتر را می سازند
جدا از سرعت بالای تک نخی این معماری نه تنها چیزی از GCN کم ندارد
بلکه با این تکنیک ها نیز میتواند پردازش هایی که سرعت بالایی احتیاج ندارند را همانند نسل قبل ظرفیت بالایی داشته باشد
IPC به معنای دستور العمل های در هر کلاک هست.
VLIW نشان داده که در بعضی از محاسبات بهتر از SIMT پردازش را محاسبه میکند
اما اجازه دستکاری کامپایلر و بهینه سازی برای انواع دیگر محاسبات خیلی پایینی داشته
در صورت ایدئال بودن کد ها برای یک WAVEFRONT میزان IPC 1.25 می دهد
در gcn این میزان نرخ ثابت 0.25 هست که در چهار کلاک یک WAVE را تکمیل می کند
RDNA از تکنیک های جدید کامپایلر و فوق استاندارد استفاده میکند که در حالت ایدئال نرخ 1 را میدهد
شایستگی نام RDNA زمانی مشخص می شود که این معماری تمام قابلیت های نسل های پیشین را دارد
مهم ترین دستاورد توانایی اجرای ILP در کنار SIMT هست که یک جهان جدیدی از قابلیت های ممکن را باز میکند
الان از بخش CU خارج می شویم
گفته شده که ناوی از RDNA نسخه اول استفاده میکند
و علت ان بهره وری از بهینه سازی هایی هست که برای GCN استفاده شده است
در غیر این صورت همانند اوایل GCN بازدهی پایینی خواهد داشت و عملا تمام بهینه سازی های قبلی را دور انداخته بودنند
بعد از جا افتادن کدنویسی های مخصوص CU های ان به لطف کنسول ها
RDNA نسخه دو که از RAY TRACING به صورت شتاب دهند سخت افزاری بهره می برد؛خواهد امد
اما با این حال ناوی حرف های زیادی خارج از CU برای گفتن دارد
در ابتدا تاخیرات کش های L1 و L2 و پهنای باند انها افزایش پیدا کرده است
تکنیک فشرده سازی رنگ در سطح عمیق استفاده شده که پهنای باند بین اجزای داخلی گرافیک را نیز افزایش داده
و بخش های جئومتری و خود پردازنده های شدر می توانند مستقیم الگوریتم فشرده را بخوانند و بنویسند !!!!
گفته شده از فلسفه طراحی ذن استفاده شده و هدف معماری با قابلیت SCALABLE بوده
این معماری را میتوان به بخش های یکسان با تعداد اجزای یکسان تقسیم کرد!!!!
در ناوی بخش مرکزی جئومتری وجود دارد که به اجزای PRIM UNIT دستور میدهد و تماما وظایف خودکار و بدون دخالت دارد!!!
ASYNC نه تنها تاخیر پایینی دارد بلکه توانسته در موارد ضروری با CONTEXT SWITCH همانند انویدیا و با سرعت دیگر پردازش ها را متوقف کند و منابع سخت افزاری بیشتر به خودش بدهد
این کار خیلی به واقعیت مجازی و vr کمک میکند
همچنین به لطف ان AMD از قابلیت ضد لگ و تاخیر پایین را در نرم افزار خودش معرفی کرده که با فعال کردن ان لگ و پاسخ دهی بالا میرود
ناوی در تعداد هسته و سطح تراشه همانند پولارس هست اما با لیتوگرافی 7 نانومتری و تعداد ترانزیستور خیلی بالاتر و مموری GDDR6
و بازدهی قویتری از وگا 64 با چهار هزار پردازنده شدر
30 درصد بهینگی و بازدهی رو فقط به لیتوگرافی اختصاص میدهیم . اما 20 درصد بازدهی بیشتر به خود معماری هست
و با کد نویسی های اختصاصی خیلی بیشتر نیز خواهد شد
اسلاید های کامل و کیفیت بالا در این لینک وجود دارد
https://gpureport.cz/info/Graphics_A...e_06102019.pdf
ما را در سایت مرجع اورکلاک دنبال می کنید
برچسب : نویسنده : استخدام کار external بازدید : 391
آرشیو مطالب
- دی 1394
- بهمن 1394
- اسفند 1394
- اسفند 1395
- فروردين 1395
- ارديبهشت 1395
- خرداد 1395
- تير 1395
- مرداد 1395
- شهريور 1395
- مهر 1395
- آبان 1395
- دی 1396
- اسفند 1396
- فروردين 1396
- ارديبهشت 1396
- خرداد 1396
- مهر 1396
- آبان 1396
- آذر 1396
- ارديبهشت 1397
- آذر 1397
- دی 1398
- بهمن 1398
- تير 1398
- مهر 1398
- آذر 1398
- فروردين 1399
- تير 1399
- بهمن 1401
- خرداد 1401
- مهر 1401
- ارديبهشت 1403